ShinyGO: a graphical gene-set enrichment tool for animals and plants
9/5/25: v.0.85. Database updated to Ensembl Release 113 and STRING-db v12.
You can still use the old versions using links on the About tab. To support this effort, please cite our paper like these 4000+ papers. Just including URL is not enough. Email Jenny (gelabinfo@gmail.com) for questions, suggestions or data contributions. Follow Dr Ge on Twitter and LinkedIn for updates. To request to add a new species/genome, fill in this Form. We will try to accommodate commonly requested genomes.
For-profit organizations: contact us for local installation or customization services.
Under active delovelopment with support from NIH. Report bugs or request features on our GitHub repository.
NO WARRANTY. Please verify results using other tools. Enrichment results may vary depending on gene ID mapping, data sources, database versions, and methods (particularily ranking).
GO Enrichment analysis, plus a lot more!
Just paste your gene list to get enriched GO terms and othe pathways for over 14,000 species, based on annotation from Ensembl and STRING-db.







Methods
All query genes are converted to ENSEMBL gene IDs or STRING-db protein IDs, as our gene ID mapping and pathway data primarily come from these sources. For model organisms, we manually compile extensive pathway lists from various public databases.
P-values are calculated using the hypergeometric test, and false discovery rates (FDRs) are computed via the Benjamini-Hochberg method to correct for multiple testing. Fold enrichment is defined as the percentage of genes in your list that are in a pathway divided by the corresponding percentage in the background genes. While FDR measures statistical significance, fold enrichment indicates effect size.
We recommend that users provide their own list of background genes, which could include all genes detected in an experiment, such as genes with probes on a DNA microarray, passed a minimal filter in RNA-seq analysis, or detected in a proteomics experiment. If no background genes are uploaded, the default is to use all protein-coding genes. Alternatively, you may select the option 'Use pathway DB for gene counts,' which calculates the background based on the total number of unique genes in the chosen pathway database, limited between 5,000 and 30,000 genes. When this option is selected, any genes in the user's original list that are not in the pathway database are excluded.
Only pathways within specified size limits, as defined by the 'Pathway size: (Min, Max)' settings, are considered. Results for smaller pathways can be noisy, but some pathways or GO terms have only a few genes. After analysis, pathways are filtered by a user-defined FDR cutoff. Significant pathways are then sorted in different ways, and only the top-ranked are shown in the table above. By default, 'Select by FDR, then by Fold Enrichment' is used, where pathways are first filtered and sorted by FDR, and then the top 20 are sorted by fold enrichment. In other words, the default setting shows the top 20 most significant pathways ranked by fold enrichment. When the 'Sort by average ranks (FDR & fold enrichment)' option is selected, pathways are sorted by the average of their ranks based on both FDR and fold enrichment. When 'Sort by FDR' is selected, pathways are ranked by FDR and only the top 20 are shown. The 'Remove redundancy' option eliminates similar pathways that share 95% of their genes and 50% of the words in their names, representing them with the pathway that has the highest significance.
Interpreting GO Enrichment Results
The Gene Ontology (GO) includes tens of thousands of terms (functional categories), each tested individually for enrichment. Hundreds or even thousands of GO terms can be statistically significant. These terms are filtered, ranked, and only the top ones are displayed. Understanding this process is crucial for interpreting GO enrichment results.
- P-value: Reflects the statistical significance of the enrichment. Lower values suggest a lower likelihood of the result occurring by chance under the null hypothesis. FDR q-values adjust P-values for multiple testing to control the proportion of type I errors.
- Fold Enrichment: Measures the magnitude of enrichment. Higher values indicate stronger enrichment and are an important metric of effect size.
- Pathway Genes: The total number of genes in a pathway or GO term.
- nGenes: The number of genes in the pathway that overlap with your gene list.
Exercise caution when interpreting FDR values of 0.01 or 0.001 for GO terms, as these levels often represent noise due to the vast number of terms tested. For a gene list of reasonable size, more significant results (FDR < 1E-5) are expected.
Large pathways, such as the cell cycle, often show smaller FDRs due to increased statistical power, while smaller pathways might have higher FDRs despite their biological relevance. Enrichment analysis tends to favor larger pathways.
With a default cutoff of FDR < 0.05, thousands of significant GO terms may be detected, though only a subset is shown. Therefore, the method of filtering and ranking these terms is crucial.
With large sample sizes, small differences can appear extremely significant. In addition to FDR, fold enrichment should also be considered when prioritizing pathways, as it reflects the strength of the enrichment. We offer several methods that consider both FDR q-values and fold enrichment.
Many GO terms are closely related (e.g., 'Cell Cycle', 'Regulation of Cell Cycle') and can dominate the top 20, obscuring other pathways. To avoid this, consider examining the top 50 terms. Additionally, use tree plots and network plots to identify clusters of related GO terms and uncover overarching themes.
Discuss the most significant pathways first, even if they do not fit your initial expectations.
A hierarchical clustering tree summarizes the correlation among significant pathways listed in the Enrichment tab. Pathways with many shared genes are clustered together. Bigger dots indicate more significant P-values. The width of the plot can be changed by adjusting the width of your browser window.
Edge cutoff:
Similar to the Tree tab, this interactive plot also shows the relationship between enriched pathways. Two pathways (nodes) are connected if they share 20% (default) or more genes. You can move the nodes by dragging them, zoom in and out by scrolling, and shift the entire network by click on an empty point and drag. Darker nodes are more significantly enriched gene sets. Bigger nodes represent larger gene sets. Thicker edges represent more overlapped genes.
Please select KEGG from the pathway databases to conduct enrichment analysis first. Then you can visualize your genes on any of the significant pathways. Only for some species.
Your genes are highlighted in red. Downloading pathway diagram from KEGG can take 3 minutes.
Your genes are grouped by functional categories defined by high-level GO terms.
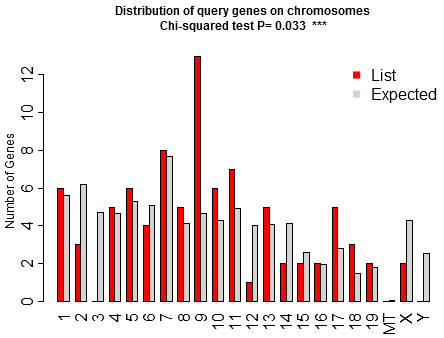
The characteristics of your genes are compared with the rest in the genome. Chi-squared and Student's t-tests are run to see if your genes have special characteristics when compared with all the other genes or, if uploaded, a customized background.
The genes are represented by red dots. The purple lines indicate regions where these genes are statistically enriched, compared to the density of genes in the background. We scanned the genome with a sliding window. Each window is further divided into several equal-sized steps for sliding. Within each window we used the hypergeometric test to determine if your genes are significantly overrepresented. Essentially, the genes in each window define a gene set/pathway, and we carried out enrichment analysis. The chromosomes may be only partly shown as we use the last gene's location to draw the line. Mouse over to see gene symbols. Zoom in regions of interest.
To validate your results independent of our algorithm and database, your genes are sent to STRING-db website for enrichment analysis. This also enables the retrieval of a protein-protein network. If it is running, please wait until it finishes. The second time it is faster.
ShinyGO is developed and maintained by a small team at South Dakota State University (SDSU). Our team consists of Xijin Ge (PI), Jianli Qi (research associate), and a few graduate students.
For feedbacks, email us, or file a bug report or feature request on our GitHub repository, where you can also find the source code. For details, please see our paper and a detailed demo. ShinyGO shares many functionalities and databases with iDEP.Citation (Just including URL is not enough!):
Ge SX, Jung D & Yao R, Bioinformatics 36:2628–2629, 2020. If you use the KEGG diagram, please also cite the papers for pathview, and KEGG.
Previous versions are still functional:
ShinyGO V0.82, based on Ensembl Release 104, archived on Sept 5, 2025
ShinyGO V0.81, based on Ensembl Release 104, archived on Feb. 3, 2025
ShinyGO V0.80, based on Ensembl Release 104, archived on Oct 25, 2024
ShinyGO V0.77, based on Ensembl Release 104, archived on Jan. 5, 2024
ShinyGO V0.76, based on Ensembl Release 104 with revision, archived on September 2, 2022
ShinyGO V0.75, based on Ensembl Release 104 with revision, archived on April 4, 2022
ShinyGO V0.74, based on Ensembl Release 104, archived on Feb. 8, 2022
ShinyGO V0.65, based on Ensembl Release 103, archived on Oct. 15, 2021
ShinyGO V0.61, based on Ensembl Release 96, archived on May 23, 2020
ShinyGO V0.60, based on Ensembl Release version 96, archived on Nov 6, 2019
ShinyGO V0.51, based on Ensembl Release version 95, archived on May 20, 2019
ShinyGO V0.50, based on Ensembl Release version 92, archived on March 29, 2019
ShinyGO V0.41, based on Ensembl Release version 91, archived on July 11, 2018
Genomes based on STRING-db is marked as STRING-db. If the same genome is included in both Ensembl and STRING-db, users should use Ensembl annotation, as it is more updated and is supported in more functional modules.
Input:
A list of gene ids, separated by tab, space, comma or the newline characters. Ensembl gene IDs are used internally to identify genes. Other types of IDs will be mapped to Ensembl gene IDs using ID mapping information available in Ensembl BioMart.Output:
Enriched GO terms and pathways:
In addition to the enrichment table, a set of plots are produced. If KEGG database is choosen, then enriched pathway diagrams are shown, with user's genes highlighted, like this one below:

Many GO terms are related. Some are even redundant, like "cell cycle" and "cell cycle process". To visualize such relatedness in enrichment results, we use a hierarchical clustering tree and network. In this hierarchical clustering tree, related GO terms are grouped together based on how many genes they share. The size of the solid circle corresponds to the enrichment FDR.

In this network below, each node represents an enriched GO term. Related GO terms are connected by a line, whose thickness reflects percent of overlapping genes. The size of the node corresponds to number of genes.

Through API access to STRING-db, we also retrieve a protein-protein interaction (PPI) network. In addition to a static network image, users can also get access to interactive graphics at the www.string-db.org web server.

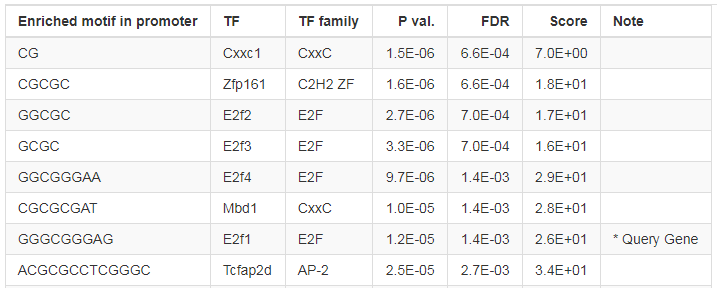
ShinyGO also detects transcription factor (TF) binding motifs enriched in the promoters of user's genes.
Sources for human pathway databases:
|
Type |
Subtype/Database name |
#GeneSets |
Source |
|
Gene Ontology |
Biological Process (BP) |
15796 |
Ensembl 92 |
|
|
Cellular Component (CC) |
1916 |
Ensembl 92 |
|
|
Molecular Function (MF) |
4605 |
Ensembl 92 |
|
KEGG |
KEGG |
327 |
Release 86.1 |
|
Curated |
Biocarta |
249 |
Whichgenes 1.5 |
|
|
GeneSetDB.EHMN |
55 |
GeneSetDB |
|
|
Panther |
168 |
1.0.4 |
|
|
HumanCyc |
240 |
pathway Commons V9 |
|
|
INOH |
576 |
pathway Commons V9 |
|
|
NetPath |
27 |
pathway Commons V9 |
|
|
PID |
223 |
pathway Commons V9 |
|
|
PSP |
327 |
pathway Commons V9 |
|
|
Recon X |
2339 |
pathway Commons V9 |
|
|
Reactome |
2010 |
V64 |
|
|
Wiki |
457 |
20180610 |
|
TF.Target |
CircuitsDB.TF |
829 |
V2012 |
|
|
ENCODE |
181 |
V70.0 |
|
|
Marbach2016 |
628 |
regulatorycircuits Release 1.0 |
|
|
RegNetwork.TF |
1400 |
7/1/2017 |
|
|
TFacts |
428 |
Feb. 2012 |
|
|
tftargets.ITFP |
1926 |
tftargets May,2017 |
|
|
tftargets.Neph2012 |
16476 |
tftargets May,2017 |
|
|
tftargets.TRED |
131 |
tftargets May,2017 |
|
|
TRRUST |
793 |
V2 |
|
miRNA.Targets |
CircuitsDB.miRNA |
140 |
V. 2012 |
|
|
GeneSetDB.MicroCosm |
44 |
GeneSetDB |
|
|
miRDB |
2588 |
V 5.0 |
|
|
miRTarBase |
2599 |
V 7.0 |
|
|
RegNetwork.miRNA |
618 |
V. 2015 |
|
|
TargetScan |
219 |
V7.2 |
|
MSigDB.Computational |
Computational gene sets |
858 |
MSigDB 6.1 |
|
MSigDB.Curated |
Literature |
3465 |
MSigDB 6.1 |
|
MSigDB.Hallmark |
hallmark |
50 |
MSigDB 6.1 |
|
MSigDB.Immune |
Immune system |
4872 |
MSigDB 6.1 |
|
MSigDB.Location |
Cytogenetic band |
326 |
MSigDB 6.1 |
|
MSigDB.Motif |
TF and miRNA Motifs |
836 |
MSigDB 6.1 |
|
MSigDB.Oncogenic |
Oncogenic signatures |
189 |
MSigDB 6.1 |
|
PPI |
BioGRID |
15542 |
3.4.160 |
|
|
CORUM |
2178 |
02.07.2017 |
|
|
BIND |
3807 |
pathway Commons V9 |
|
|
DIP |
2630 |
pathway Commons V9 |
|
|
HPRD |
7141 |
pathway Commons V9 |
|
|
IntAct |
11991 |
pathway Commons V9 |
|
Drug |
GeneSetDB.MATADOR |
266 |
GeneSetDB |
|
|
GeneSetDB.SIDER |
473 |
GeneSetDB |
|
|
GeneSetDB.STITCH |
4616 |
GeneSetDB |
|
|
GeneSetDB.T3DB |
846 |
GeneSetDB |
|
|
SMPDB |
699 |
pathway Commons V9 |
|
|
CTD |
8758 |
pathway Commons V9 |
|
|
Drugbank |
2563 |
pathway Commons V9 |
|
Other |
GeneSetDB.CancerGenes |
23 |
GeneSetDB |
|
|
GeneSetDB.MethCancerDB |
21 |
GeneSetDB |
|
|
GeneSetDB.MethyCancer |
54 |
GeneSetDB |
|
|
GeneSetDB.MPO |
3134 |
GeneSetDB |
|
|
HPO |
6785 |
May,2018 |
|
Total: |
|
140,438 |
|
Sources for mouse pathway databases:
|
|
|
|
|
|
Type |
Source |
#Sets |
Note |
|
Co-expression |
Literature |
8,742 |
Differentially expressed genes from 2526 studies |
|
|
MSigDB |
3,964 |
Molecular Signature Database, v.6.0 |
|
|
L2L |
248 |
List of lists, v.2006.2 |
|
|
CancerGenes* |
23 |
Cancer gene lists |
|
|
GeneSigDB |
494 |
Gene Signature Database, R.4 |
|
Gene |
GO_BP |
11,943 |
V2017.5 |
|
Ontology |
GO_MF |
2,932 |
|
|
|
GO_CC |
1,475 |
|
|
Curated |
Biocarta* |
176 |
Metabolic and signaling pathways |
|
pathways |
PANTHER |
151 |
Ontology-based pathway database, v3.4.1 |
|
|
WikiPathways* |
146 |
Open platform for pathway curation |
|
|
INOH* |
73 |
Integrating network objects with hierarchies |
|
|
NetPath* |
25 |
Signal transduction pathways |
|
Metabolic |
KEGG |
314 |
Metabolic pathways, R.82.0 |
|
pathways |
EHMN* |
53 |
Edinburgh human metabolic network |
|
|
MouseCyc |
321 |
Mouse Biochemical Pathways , v2013.7 |
|
Drug |
CTD* |
910 |
The Comparative Toxicogenomics Database |
|
related |
SIDER* |
460 |
Side Effect Resource |
|
|
MATADOR* |
248 |
Manually Annotated Targets and Drugs Online Resource |
|
|
DrugBank* |
136 |
Open data drug and target database |
|
|
SMPDB* |
74 |
Small Molecule Pathway Database |
|
miRNA |
miRDB |
1,912 |
miRNA target prediction and annotations, v 5.0 |
|
Target |
microRNA.org |
314 |
Predicted miRNA targets, v.R2010 |
|
Genes |
Grimson et al. |
179 |
Predicted miRNA targets. v.6.2 |
|
|
TarBase |
84 |
Experimentally validated miRNA targets, v.6.0 |
|
|
miRTarBase |
775 |
Experimentally validated miRNA targets, V6.1 |
|
|
MicroCosm |
464 |
Predicted targets |
|
|
PicTar |
35 |
Predicted miRNA sites, v. 2007.3 |
|
TF Target |
TFactS* |
101 |
Predicted TF targets |
|
Genes |
TRED |
99 |
Confirmed TF target genes, v.2013.7 |
|
|
CircuitsDB |
94 |
Mixed miRNA/TF regulation, v. 2012 |
|
|
TRANSFAC |
78 |
Confirmed TF binding sites, v7.0 |
|
Others |
Location |
341 |
Genomic location on chromosomes, v.2017 |
|
|
HPO* |
1,518 |
The human phenotype ontology |
|
|
STITCH* |
3,929 |
Interaction networks of chemicals and proteins |
|
|
MPO* |
2,943 |
Mammalian Phenotype Ontology |
|
|
T3DB* |
722 |
Database of common toxins and their targets |
|
|
PID* |
193 |
Pathway Interaction Database |
|
|
MethyCancer* |
50 |
Human DNA methylation and cancer |
|
|
MethCancerDB* |
19 |
Aberrant DNA methylation in human cancer |
|
|
Total |
46,758 |
*Secondary data from GeneSetDB |
Changes:
2/3/25: v.0.82. Fix issues caused by multiple ENSEMBL IDs for the same gene on patched chromosomes, causing inaccurate enrichment results. Duplicated ENSEMBL IDs are now ignored.
10/26/24: v0.81. Disabled the switch of species during analysis. Fixed errors with STRING tab when STRINGdb species are used. If a gene ID maps multiple Ensembl genes, all are kept for enrichment.
10/25/24: Migrated to new server. Upgraded R to 4.4.0.
4/21/2024: New barchart with GO terms on the bars.
4/12/2024: Max set size is increased to 5000 from 2000. Some meaningful GO terms (RNA biosynthetic proc.) contains 4000+ genes.
4/21/2024: New barchart with GO terms on the bars.
4/20/2024: UI adjustment
4/12/2024: Max set size is increased to 5000 from 2000. Some meaningful GO terms (RNA biosynthetic proc.) contains 4000+ genes.
1/5/2024: ShinyGO 0.80 becomes default. You have to select your species first. Database is updated to Ensembl release 107 which includes 620 species: 215 main, 177 metazoa, 124 plants, 33 protists and 1 bacteria. We also included 14,094 species from STRING-DB 11.5.
5/1/2023: ShinyGO 0.80 release in testing mode. Thanks to Jenny's hardwork, we update to Ensembl release 107 which includes 620 species: 215 main, 177 metazoa, 124 plants, 33 protists and 1 bacteria. We also included 14,094 species from STRING-DB 11.5.
Jan. 19, 2023: Thanks to a user's feedback, we found a serious bug in ShinyGO 0.76. As some genes are represented by multiple gene IDs in Ensebml, they are counted more than once in calculating enrichment. We believe this is fixed. If you pasted Ensembl gene IDs to ShinyGO 0.76 between April 4, 2022 and Jan. 19, 2023, please rerun your analysis. ShinyGO has not been throughly tested. Please always double check your results with other tools such as G:profiler, Enrichr, STRING-db, and DAVID.
Oct 26, 2022: V. 0.76.3 Add hover text. Change plot styles. When users select "Sort by Fold Enrichment", the minimum pathway size is raised to 10 to filter out noise from tiny gene sets.
Sept 28, 2022: In ShinyGO 0.76.2, KEGG is now the default pathway database. More importantly, we reverted to 0.76 for default gene counting method, namely all protein-coding genes are used as the background by default. The new feature introduced in 0.76.1, which uses the pathway database to determine total number of genes in the background, can be turned on as an option ('Use pathway database for gene counts'). This is based on feedback from some users that when using smaller pathway databases, such as KEGG, the new method changes the P values substantially.
Sept 3, 2022: ShinyGO 0.76.1. In this small improvement, we improved how we count the number of genes for calculating P value. A gene must match at least one pathway in the selected pathway database. Otherwise this gene is ignored in the calculation of P values based on hypergeometric distribution. This applies to both query and background genes.
April 19, 2022: ShinyGO 0.76 released. Improved pathway filtering, pathway sorting, figure downloading. Version 0.75 is available here.
April 17, 2022: Add more flexiblity for download figures in PDF, SVG and high-res PNG.
April 8, 2022: Add features to remove redundant pathways. Add filter to remove extrmely large or small pathways. Changed interface to always show KEGG tab.
Mar. 7, 2022: Fixed an R library issue affected KEGG diagrams for some organisms.
Feb. 26, 2022: Fixed a bug regarding the Plot tab when background genes are used. Background genes were not correctly used to calculate the distributions of various gene characteristics. If these plots are important in your study, please re-analyze your genes.
Feb. 19, 2022: R upgraded from 4.05 to 4.1.2. This solved the STRING API issues. Some Bioconductor packages are also upgraded.
Feb. 8, 2022: ShinyGO v0.75 officially released. Old versions are still available. See the last tab.
Nov. 15, 2021: Database update. ShinyGO v0.75 available in testing mode. It includes Ensembl database update, new species from Ensembl Fungi and Ensembl Protists, and STRINGdb (5090 species) update to 11.5.
Oct25, 2021: Interactive genome plot. Identificantion of genomic regions signficantly enriched with user genes.
Oct.23, 2021: Version 0.741 A fully customizable enrichment chart! Switch between bar, dot or lollipop plots. Detailed gene informations with links on the Genes tab.
Oct. 15, 2021: Version 0.74. Database updated to Ensembl Release 104 and STRING v11. We now recommends the use of background genes in enrichment analysis. V.0.74 is much faster with even large set of background genes.